Shocher A, Cohen N, Irani M. “Zero-Shot” Super-Resolution using Deep Internal Learning[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 3118-3126.
1. Overview
1.1. Motivation
- Existing SR supervised method rely on prior training (restricted to training data)
- Non-ideal acquisition process in reality (not always bicubic, bilinear), old photo, noisy image, biological data, phone image

- Natural images have strong internal data repetition (at different location and scale). Internal entropy of patches inside a single image is much smaller than the external entropy of patches in a general collection of natural images

论文提出Zero-Shot SR方法
- Not rely on prior training
- Exploit internal recurrence of information inside a single image
- Perform SR on real image where the acquisition process is unknown and non-ideal
- Train a small CNN at test time only from the LR image and its downscaled (self-supervision)
- train + test time is comparable to the test time of SotA
1.2. Contribution
- First unsupervised CNN-based SR method
- Handle non-ideal condition
- Not require pretraining
- SR any size
1.3. Related Work
Supervised
- EDSR
- VDSR
Unsupervised (not deep learning)
- Blind-Deblurring
- Blind-Dehazing
- Blind-SR
1.4. Model

- Downscaling test image to many smaller version of itself (HR-fater vs LR-son).
- Gradually SR. Several intermediate scale-factors
- 4 Rotations (0, 90, 180, 270) and 2 flip
- Learn residual
- Select rate based on proportional to the size of the HR-father. Size close to test image has high rate
- 8 output of test image (4R x 2F), take median + back-projection
- More intermediate scale-factor increase accuracy
- Time independent of image size and scale-factor
- 54 s/img on GPU, EDSR+ 20s on 200x200 image, EDSR 5min on 800x800 image
1.5. Parameters
- Downscaling kernel
- Scale-factor
- Number of gradual scale increase
- Whether Backprojection
- Whether add noise (learn to ignore uncorrelated cross-scale information)
1.6. Future Work
- Combine Internal-Learning with External-Learning in a single computational framework
2. Experiments
2.1. Ideal Case (bicubic kernel)
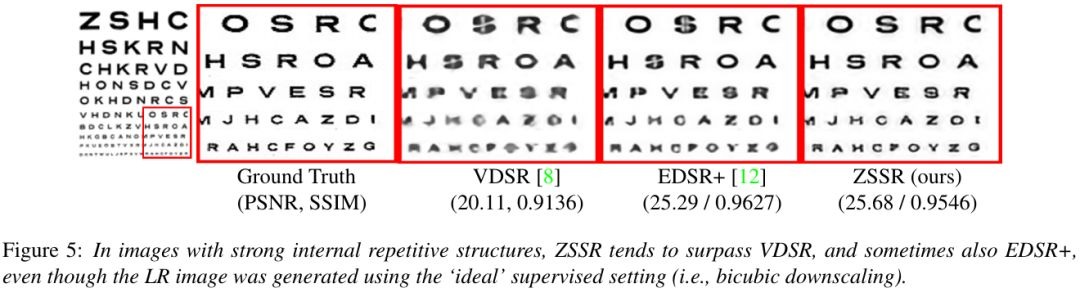


2.2. Non-ideal Case
2.2.1. Deviate from bicubic
Random Gaussian Kernel
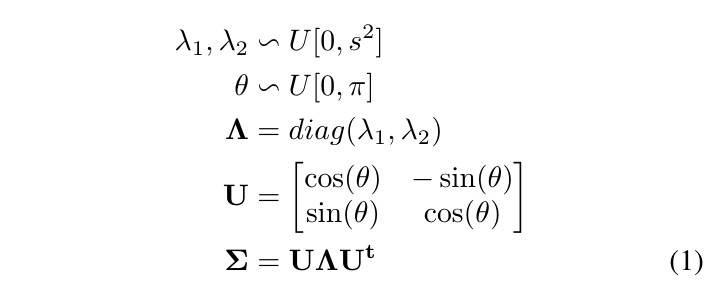
Two case apply to ZSSR
- Blind-SR evaluate kernel, feed to ZSSR
- True kenel feed to ZSSR
Solution
- Accurate downscaling model is more important than sophisticated image prior
- Wrong downscaling kernel lead to oversmoothed SR result

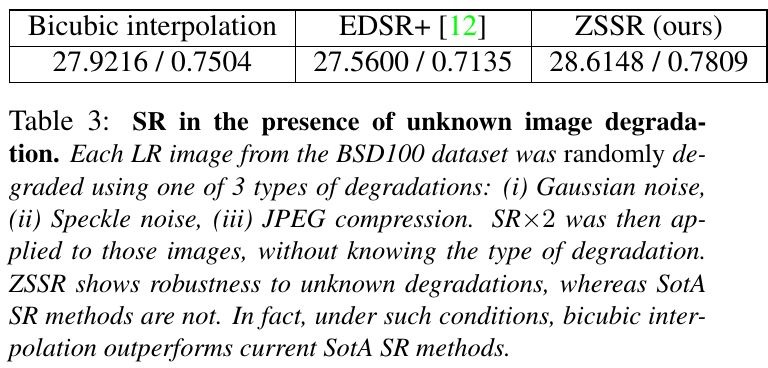
2.2.2. Low-quality LR image
- Gaussian noise
- Speckle noise
- JPEG compression